Text¶
This guide provides an overview and brief instructions on using Text blocks to parse and create text files based on workflow data.
Text is a beta block
The Text block is in beta. Future pSeven Enterprise updates will keep compatibility with the current version of the block, but this beta version may still have some features missing or not yet working as intended.
Getting started¶
With the Text block, you can create text files, populating an input file or template with input port data, as well as parse and retrieve data from an input text file, and then issue that data on output ports. This block is typically used to create input and output adapters for integrating third-party programs into pSeven Enterprise workflows. Its configuration is based on a text template that, as a rule, is a sample of the input or output file of a certain program.
If running a third-party program requires an input file with parameters, the Text block can produce such a file at workflow run time by using a template that represents a sample of the program's input file. The block reads text from its input file or template, replaces certain portions of that text with values from its input ports, and then issues an output file containing the resulting text. The workflow can use the output file obtained in this way as an input file for the program being run.
flowchart TB
template[\ /]
data[\ /]
processing[[Insert data into text]]
file[\ /]
data --> |Input data| processing
template -->|Input file/Template| processing
processing -->|Output file| fileIf the program saves its results to a text file, the Text block can be used to parse that file in order to transfer the results to other blocks in the workflow. Similarly, the block can process the program's standard output, since the stdout stream can easily be redirected to a text file. The Text block retrieves data from certain portions of the text in the input file, and issues the data thus obtained to its output ports. The text template in this case is only used as a sample of the program results file when configuring the block.
flowchart TB
file[\ /]
data[\ /]
processing[[Retrieve data from text]]
file -->|Input file| processing
processing -->|Output data| dataThe general logic of the Text block is always the same:
- Take the input file along with the values received on the input ports. The input file may be the same file that was loaded as the template, or a file produced by another block.
- Copy the input file to memory and apply operations to this copy, such as write input values or retrieve values to output.
- Save the modified contents of the input file to the output file, and issue the values retrieved from the input file on the block output ports.
Above are outlined two typical cases of using the Text block. However, these are not some presets - rather, they are two commonly used combinations of regular settings. For details on these two setups, see Building program input file and Parsing program output file. Other setups are also possible - for example, the block can read from, and write to, the same file at once, if needed.
Text blocks can be used in an optimization workflow that runs an external solver program for function evaluations. In such a workflow, one Text block receives values of variables from the optimizer block, such as Design space exploration, and creates an input file for the solver program; the other one receives the program's output file, reads the result values and sends them to the optimizer block.
flowchart LR
subgraph requests [" "]
direction TB
optimizer-out(Optimizer)
text-in(Text block 1)
solver-in(Program)
optimizer-out -->|Requests| text-in
text-in -->|Program input file| solver-in
end
subgraph responses [" "]
direction BT
optimizer-in(Optimizer)
text-out(Text block 2)
solver-out(Program)
solver-out -->|Program output file| text-out
text-out -->|Responses| optimizer-in
end
requests ~~~ responsesWith the Text block, you can also generate complex text reports, create custom configuration files for your workflows, and perform other text-related tasks. It also supports Python scripting and provides the ability to combine general Python code with its built-in capabilities.
Input and output files¶
The input and output files are transferred using relative paths within the
working directory of the Text block. Use the Input file path and
Output file path input ports to specify the paths. The path is relative to
the working directory root, with forward slashes (/) as path separators, for
example: data/template.txt - the template.txt file in the data subfolder
of the working directory.
During a workflow run, the block expects to find the file specified by the
Input file path port within its working directory. If the input is an
existing file (a template), place it by that path relative to the block's
working directory prototype when setting up the workflow. If the input file is
created by a certain block during a workflow run, set up a common working
directory for that block and the Text block, and pass the file path and name
from that block to the Input file path port of the Text block.
The Text block stores its output file inside its working directory with
the file path and name specified by the Output file path input port. To
pass the output file to another block, set up a common working directory
for that block and the Text block, and pass the file path and name from
the Output file path output port of the Text block to the block that
reads the file.
To set up a common working directory for two or more blocks, group them all into one Composite block - its working directory is then common for all its nested blocks (see Working directory management for details).
Understanding the configuration dialog¶
Typically, you configure the Text block by using a text template, in which you select text elements that match the variable values to read or write.
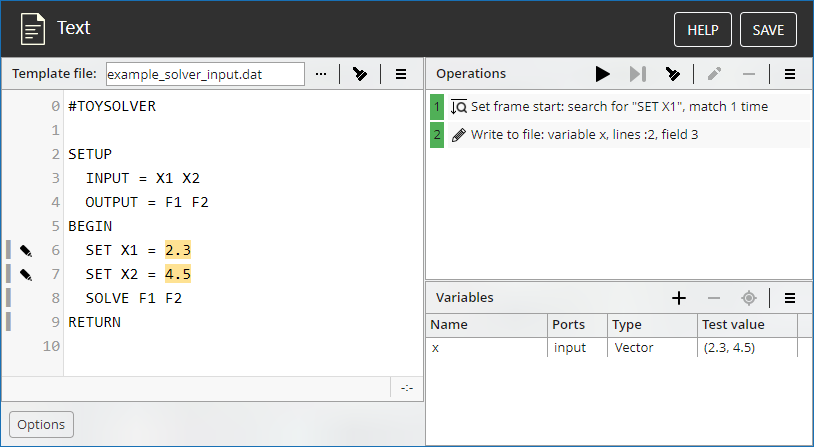
The area on the left side of the block configuration dialog displays the template loaded from the selected file. The name of that file appears in the "Template file" field.
The template serves as a sample input file when configuring
the block to retrieve data from text. The block can also
compose an output file by substituting its input values into
the template text. By using the toolbar in that area, you
can select a different file to load the template from (the
![]() button)
or delete the template from the block configuration (the
button)
or delete the template from the block configuration (the
![]() button).
button).
In the upper right part of the block configuration dialog, the Operations pane displays the sequence of operations that the block will perform when running within the workflow, such as reading or writing values located in certain parts of the text. Here you can use the toolbar to edit the operation sequence and test it before running the block in the workflow (see Operations and Operations check for details).
Beneath the Operations pane, the Variables pane lists the block variables, their names, types and test values. In this pane, you can view or change variables that were added from the template, as well as create additional variables (see Variables for details). Test variable values shown here are used when testing operations. The toolbar provides a command for reviewing variable values in operation check results: it locates the variable values in the template that have been retrieved or changed by the tested operations. Use this command when checking operations to verify that the test values of the variables match the current values in the template text (see Variable values review for details).
Building program input file¶
To use the Text block to create a text file (for example, the input file for a certain program), a sample of such a file must be provided - this can be a file that the Text block receives during the workflow run, or a template file selected when configuring the Text block. The block builds the output file using the provided sample in which certain parts of the text are replaced with values received from other blocks, workflow parameters, or other sources.
Follow these steps in the Text block configuration dialog:
-
In the "Template file" field, specify the file containing template text. To select the desired file, click the
 button
next to that field.
button
next to that field.The block configuration dialog displays the text held in the template file you have selected, which is used to configure and test variables and operations.
-
In the template text displayed in the configuration dialog, select the rectangle area embracing values to replace when building the output file.
When you are done, a pop-up box appears, prompting you to specify the input variable whose values will replace the values you have selected in the template text. In the pop-up box, enter the name of the new variable or select an existing variable, and then click the write button
 .
Note that in this case you must create or select an input
variable: the block receives the value of that variable
from the input port and writes it to the output file.
.
Note that in this case you must create or select an input
variable: the block receives the value of that variable
from the input port and writes it to the output file.After you specify a variable, all operations necessary to substitute the values of that variable into the output file will be automatically created in the block configuration. All operations created in this way are displayed in the block configuration dialog Operations pane, and tested automatically. You can also test them by hand as described in Testing the setup.
If the values to be replaced are in different rectangular areas of the template, follow the steps above for each of those areas. For more information on setting up block variables and operations by selecting replacement values in the template, see Using quick selection. You can also create and configure variables and operations directly in the configuration dialog Variables pane and Operations pane, respectively.
Parsing program output file¶
When parsing a text file (for example, the output file of a certain program), the Text block outputs the values found in the input file it normally receives at workflow run time. In this case, the actual input file cannot be provided when configuring the block. To simplify the block configuration steps, a template file is used that represents a sample of the input file.
Note that in this case you are not required to specify a sample of the input file when configuring the block. However, your workflow should provide a link through which the Text block can receive the input file at run time.
Follow these steps in the Text block configuration dialog:
-
In the "Template file" field, specify the file representing a sample of the input file. To select the desired file, click the
button
next to that field.This file is used as a template when configuring the block, so it must match the input file the block receives at workflow run time. Note that the template just simplifies the steps for setting up the block's variables and operations; when parsing the input file at workflow run time, the template is not used in any way.
The block configuration dialog displays the text held in the template file you have selected, which is used to configure and test variables and operations.
-
In the template text displayed in the configuration dialog, select the rectangle area indicating the location of the values to retrieve when parsing the input file.
When you are done, a pop-up box appears, prompting you to specify the output variable that will be assigned the values found in the input file within the area you have selected in the template text. In the pop-up box, enter the name of the new variable or select an existing variable, and then click the read button
 .
Note that in this case you must create or select an output
variable: the block assigns that variable the values from the
input file, and then issues the variable value through the
respective output port.
.
Note that in this case you must create or select an output
variable: the block assigns that variable the values from the
input file, and then issues the variable value through the
respective output port.After you specify a variable, all operations necessary to locate, read, and output the values from the input file will be automatically created in the block configuration. All operations created in this way are displayed in the block configuration dialog Operations pane, and tested automatically. You can also test them by hand as described in Testing the setup.
If the values to be read from the input file are located in different rectangular areas of the template, follow the steps above for each of those areas. For more information on setting up block variables and operations by selecting areas of the template that contain values to read, see Using quick selection. You can also create and configure variables and operations directly in the configuration dialog Variables pane and Operations pane, respectively.
Using quick selection¶
Quick selection of values in the template text is intended to simplify the Text block configuration steps. This method is not as flexible as directly adding and configuring variables and operations, and it does not cover all uses of this block. It is efficient when the values in question fill a rectangular area in the template text, that is, form a single column, single row, or table of multiple rows and columns. If you select such a rectangular area in the template text, the block settings automatically add the operations of relocating the working frame through the text file and substituting or retrieving values within that frame.
Note that only the values to be replaced or retrieved should be selected in the template, not entire strings. For typical block setups using quick selection, see Building program input file and Parsing program output file.
Examples of using quick selection:
- A numeric or string value selected in the template text maps to a scalar variable.
- A row or column of values selected in the template text maps to a vector variable. If you need to select one of several columns, quick selection works only if the columns do not overlap, that is, each value is located in only one of the columns.
- A rectangular table of values selected in the template text maps to a matrix variable. In this case, quick selection works only if all rows of the selected area contain the same number of values, and the same is true for its columns, that is, the selected values form a rectangular matrix.
Along with numeric values, the names of the selected values - for example, the names of rows or columns, can also be included in the quick selection area. Such an area maps to a variable that is a dictionary, that is, an associative array of (key, value) pairs, where the keys are the names selected in the template text.
A dictionary variable can be useful in a situation where the quick selection area covers the values of a large number of named parameters, since it eliminates the need to create a separate variable for each parameter. In addition, unlike a vector or a list, a dictionary allows an arbitrary order of the components corresponding to different parameters. The value in a dictionary (key, value) pair is typically a vector corresponding to the selected row or column. To represent scalar values in a dictionary, one can use either scalar data types or one-component vectors.
A dictionary variable can also be used in the case of a different number of values in the selected rows or columns. However, the operations in this case will have to be configured manually in the Operations pane.
Testing the setup¶
Before running a workflow that uses the Text block, you can test it to make sure the results of its operations are correct. The operations added during quick selection are tested automatically, and the test results are displayed in the block configuration dialog. Manual testing is also provided - for example, to test the entire sequence of operations added by multiple quick selections.
Operations check¶
To check operations, use the toolbar in the Operations pane. With this toolbar, you can:
- Run and check the entire sequence of operations specified in the
block configuration (the
 button).
button). - Run and check the next untested operation (the
 button).
button). - Delete check results, that is, remove all test values from the
template and mark all operations as unchecked (the
 button).
button).
Note that you must assign test values to the appropriate input variables before testing write data and insert data operations. The test value is specified in the "Test value" field in the Variables pane.
When checking operations, test values of the variables are highlighted in the template text. The configuration dialog only displays the value changes that have occurred as a result of the check, whereas the template itself remains unchanged.
Checking the operation of writing data to a file substitutes the test value of the variable into the template text. Checking the operation of reading data from a file enters the values from the template text into the "Test value" field of the associated variable in the Variables pane.
The result of checking the operation of reading data from a file is a new test value for the variable. However, if this operation assigns values from the template to only some components of a vector or matrix variable, that variable must initially be set to a certain test value. The initial value determines the parameters of the variable, such as the number of vector components or the number of matrix rows. This information is required to verify that values from the template text have been properly entered into the respective components of the variable. If the operation is configured to populate all components of the variable, the initial test value is not used.
Operation check failures are marked in red in the list of operations and in the template text, and error messages are displayed beneath the template text.
Variable values review¶
To analyze test results, you can view variables' test values read from the template text and view changes made by writing variables' test values to the template text.
The Variables toolbar provides a command to search the template text
for test values of variables that were written or read during testing:
after testing, select a variable in the Variables pane and click the
![]() button. The template text will
highlight the lines with the test values of the selected variable. If
the given variable is used in multiple operations, then first highlighted
are only the lines corresponding to the first of those operations. Click
the
button. The template text will
highlight the lines with the test values of the selected variable. If
the given variable is used in multiple operations, then first highlighted
are only the lines corresponding to the first of those operations. Click
the ![]() button again to highlight
the lines corresponding to the next operation.
button again to highlight
the lines corresponding to the next operation.
Note that the variable values review described above can only be used after a successful operations check. If you select a variable used in an operation that has not passed the operations check, attempting to search the template text for test values of that variable would cause an error message.
Variables¶
The block configuration dialog provides the Variables pane for managing variables. In this pane, you can add or remove variables, as well as view or change the properties of existing variables, including those created using quick selection.
Each variable is automatically assigned a port of the same name for receiving or issuing the values of that variable. If a variable writes values to the text file, it is assigned an input port - hence the name input variable. If a variable is used to read values from the text file, it is assigned an output port - this is, accordingly, output variable. A variable can be assigned a pair of ports - input and output, in which case the variable can be used both to read and write values from the file.
Each variable corresponds to a list row in the Variables pane. Variable properties are represented by list row fields to view or edit, including:
-
Name
The name identifies the variable and its port/s. The name is assigned to the variable when it is created, you can change the name in the Variables pane. When renaming a variable, the name its port/s changes accordingly.
Each variable must have a unique name among all variables within the block configuration, and it must contain only allowed characters. The following characters are not allowed in variable names:
.<>:"/\|?*. -
Ports
This property associates with the variable the port(s) to receive and/or issue data. Configuration options:
input(input port that receives variable values from the workflow),output(output port that issues variable values into the workflow),both(pair of ports, input and output). The port name is the same as the variable name. -
Type
The type of the variable is a characteristic of its value, it can be a number, a string, a vector, a matrix, and so on. The type is assigned to the variable when it is created, you can change the type in the Variables pane. Note that the current test value of the variable is lost if you change the type of that variable.
-
Test value
The variable's test value is used to check operations when testing the block setup. A certain test value must be set in the case of an input variable and may be required for an output variable as well, see Operations check for details.
Operations¶
The block configuration dialog provides the Operations pane for managing operations. In this pane, you can add or remove operations, view or change the properties of existing operations, including those created using quick selection, and also check operations. Operations define block actions for parsing and building text files:
- Set frame start - search the current working frame for a string matching the specified condition and set the first string of the current working frame according to the found string.
- Set frame end - search the current working frame for a string matching the specified condition and set the last string of the current working frame according to the found string.
- Reset frame - set the start and end of the current working frame to the first and last line of the text file, respectively.
- Write value - replace the specified pieces of text in the current working frame with the value of the specified variable.
- Read value - assign the specified variable the value read from the specified pieces of text in the current working frame.
- Insert value - insert additional text strings and write the value of the specified variable into them.
- Python code - run the specified Python script.
Reading and writing values from a text file is a two-step process. At the first step, a working frame is created by searching the text of the file, for this, the operations of setting the first string and last string of the working frame Set frame start and Set frame end are used. The numbering of text strings in the working frame is arranged as follows: the index of the first string is 0, the indices of the next lines are 1, 2, 3, and so on. The Write value, Read value, and Insert value operations then use indices to specify the strings in which the desired values reside. In this way, it is possible to process values located in different parts of the text, since the desired part is first searched and its lines are indexed using the working frame.
If the first and last strings of the work frame are not set using the appropriate operations, its first string is the first line of the file, and the last string is the last line of the file. In cases where the desired values are always in the same part of the text, the frame setting operations can be omitted by specifying the line index, counted from the beginning of the file. Note that in this case indexing also starts from zero: the first line of the file is actually the first string of the working frame and its index is 0.
When setting the start or end of the working frame, note that the Set frame start operation looks for the new start string, moving down the text from the first string of the current working frame, while the Set frame end looks for the new ending string, moving up in text from the last string of the current working frame. For this reason, to avoid unwanted effects, before setting up a new working frame, the Reset frame operation is used to set the first and last strings of the current working frame to the beginning and end of the entire text file.
Set frame start¶
The Set frame start operation searches down the text from the beginning to the end
of the current working frame. When a string is found that matches the search criteria,
the first string of the new working frame is set in the vicinity of the string found.
The search is performed only within the current working frame. If a matching string cannot be found in the current working frame, a new working frame is not set, even if the file contains a line that matches the search criteria.
Note that the current working frame does not necessarily start at the first line
of the file and does not necessarily continue to the last line of the file. The
beginning of the current working frame is specified by the previous Set frame start
operation, if that operation was performed. Similarly, the end of the current working
frame can be specified by the Set frame end operation. If you want
to search the entire file, you must first apply the Reset frame
operation to reset the current working frame.
To specify search criteria, enter a search string or regular expression in the "Search down for a line containing" field. The default is to search for a string of text that contains the search string specified in that field. To search for a string of text that matches the specified regular expression, select the "Search pattern is a regular expression" check box.
Strings that match the specified search criteria are skipped until the number of such strings reaches the value specified by the "Stop at N match" setting. The default is to stop the search at the first matching string.
Once a matching string is found, the beginning of the new working frame can be set
a few strings up or down, depending upon the "After matching, move
Set frame end¶
The Set frame end operation searches up the text from the end to the beginning
of the current working frame. When a string is found that matches the search criteria,
the last string of the new working frame is set in the vicinity of the string found.
The search is performed only within the current working frame. If a matching string cannot be found in the current working frame, a new working frame is not set, even if the file contains a line that matches the search criteria.
Note that the current working frame does not necessarily continue to the last line
of the file and does not necessarily start at the first line of the file. The end
of the current working frame is specified by the previous Set frame end operation,
if that operation was performed. Similarly, the beginning of the current working
frame can be specified by the Set frame start operation. If you
want to search the entire file, you must first apply the Reset frame
operation to reset the current working frame.
To specify search criteria, enter a search string or regular expression in the "Search up for a line containing" field. The default is to search for a string of text that contains the search string specified in that field. To search for a string of text that matches the specified regular expression, select the "Search pattern is a regular expression" check box.
Strings that match the specified search criteria are skipped until the number of such strings reaches the value specified by the "Stop at N match" setting. The default is to stop the search at the first matching string.
Once a matching string is found, the end of the new working frame can be set
a few strings up or down, depending upon the "After matching, move
Reset frame¶
The Reset frame operation sets the current working frame to cover the entire text
file (default setting). As a result of this operation, the current working frame begins
with the first line of the file and ends with its last line. This operation has no
settings to configure.
Write value¶
The Write value operation is used to substitute the value of the specified variable
in place of the specified text fragments in the working frame. This operation only
allows you to substitute values into existing strings of text; to add new strings,
use the Insert value operation.
The Write value operation has the following settings:
-
Variable
When creating an operation, you can select an existing variable or enter a name for a new variable that will be created along with this operation.
-
Elements
In the case of a vector or matrix variable, you can specify its components, the values of which will be substituted into the text. The components of a vector variable are the coordinates of the vector; the components of a matrix variable are the rows of the matrix. Component numbering starts from zero, so the index of the first component is 0. Configuration options:
- All - substitute the values of all components.
- Index - substitute the value of one component with the specified index - the value of a certain coordinate of the vector or the vector value of a certain row of the matrix.
- Slice -
substitute component values that are defined by a slice of indices in
Python format
start:stop:step(start index, end index, slice step).
-
Lines
You must specify the index of the string into which the operation will substitute the value of the variable. The string numbering starts from the first string in the working frame, so the index of the frame's start string is 0. To substitute the values of the variable components, you can specify the indices of several strings as a list of individual numbers and numeric ranges (for example,
2,5,7-11) or a slice of indices in Python formatstart:stop:step(start index, end index, slice step). -
Delimiters
This setting specifies the character sequences to separate the fields for substituting the values of the variable components. The default field delimiter is one or more spaces or tabs ("Whitespaces and tabs" setting). Other field delimiters can be specified using a regular expression ("Regex" setting).
With the "Regex" setting, you can specify one or more characters as a field delimiter, or a regular expression. In the latter case, the field delimiter is any substring that matches the regular expression specified. For example, you can use the regular expression
>|<to specify delimiters in a file with XML markup tags (the vertical bar|here denotes the logical OR). -
Fields
This setting specifies the indices of the string fields into which the values of the variable components will be substituted. The fields are parts of the string that are separated according to the "Delimiters" setting. The field numbering starts from the leftmost field in the line, the index of that field is 0. You can specify the indices of multiple fields as a list of individual numbers and numeric ranges (for example,
0,2-4) or a slice of indices in Python formatstart:stop:step(start index, end index, slice step). To indicate the indices of all fields in the string, use the slice:, which denotes a sequence of indices from zero to the last index in increments of 1. -
Format style
Use this setting to specify the format for representing numbers in the text. Configuration options:
- No format -
Python default formatting (
%sformat). - C -
formatting via C language specifiers - for example,
%.5fto represent a floating-point number with 5-digit precision. - Fortran -
formatting via Fortran language specifiers - for example,
F10.3to represent a floating-point number with 3-digit precision in a 10-character field.
- No format -
Python default formatting (
-
Decimal separator
Use this setting to specify the decimal separator character in the text representation of floating-point numbers. You can select either a point (dot) or a comma as the decimal separator. The default is the separator specified by the Decimal separator option.
This operation substitutes into the text the value assigned to the variable as of the time the operation was started. Typically, a variable is assigned the value received through its input port, but there are other ways to set a variable's value. For example, the value for a variable can be read from the input file using the Read value operation, and then substituted elsewhere in the file. A variable can also be assigned a value using the Python script specified by the Python code operation.
Read value¶
The Read value operation reads values from the specified pieces of text
in the working frame and assigns them to the specified variable.
The Read value operation has the following settings:
-
Variable
When creating an operation, you can select an existing variable or enter a name for a new variable that will be created along with this operation.
-
Elements
In the case of a vector or matrix variable, you can specify its components, which will be assigned values from the text. The components of a vector variable are the coordinates of the vector; the components of a matrix variable are the rows of the matrix. Component numbering starts from zero, so the index of the first component is 0. Configuration options:
- All - assign values to all components.
- Index - assign the value to one component with the specified index - the scalar value to a certain coordinate of the vector, or the vector value to a certain row of the matrix.
- Slice -
assign values to components that are defined by a slice of indices in
Python format
start:stop:step(start index, end index, slice step).
For a variable with the "Index" or "Slice" setting, you must specify a test value. See Operations check for details on the variable test value.
-
Lines
You must specify the index of the string from which the operation will read the values for the variable. The string numbering starts from the first string in the working frame, so the index of the frame's start string is 0. To read and assign the values to the variable components, you can specify the indices of several strings as a list of individual numbers and numeric ranges (for example,
2,5,7-11) or a slice of indices in Python formatstart:stop:step(start index, end index, slice step). -
Delimiters
This setting specifies the character sequences that separate the fields from which to read the values for the variable components. The default field delimiter is one or more spaces or tabs ("Whitespaces and tabs" setting). Other field delimiters can be specified using a regular expression ("Regex" setting).
With the "Regex" setting, you can specify one or more characters as a field delimiter, or a regular expression. In the latter case, the field delimiter is any substring that matches the regular expression specified. For example, you can use the regular expression
>|<to specify delimiters in a file with XML markup tags (the vertical bar|here denotes the logical OR). -
Fields
This setting specifies the indices of the string fields from which to read the values for the variable components. The fields are parts of the string that are separated according to the "Delimiters" setting. The field numbering starts from the leftmost field in the line, the index of that field is 0. You can specify the indices of multiple fields as a list of individual numbers and numeric ranges (for example,
0,2-4) or a slice of indices in Python formatstart:stop:step(start index, end index, slice step). To indicate the indices of all fields in the string, use the slice:, which denotes a sequence of indices from zero to the last index in increments of 1. -
Convert to
If the "Variable" setting specifies a new variable name, select the desired data type from the drop-down list. In this case, the new variable will have the data type specified by the "Convert to" setting. If an existing variable is selected in the "Variable" setting, its data type is determined automatically and displayed in the "Convert to" field.
Note that this operation assigns a value to the variable, but the block outputs the variable value only after completing all operations. Therefore, reading data from the file and storing it in some variable does not prevent the value of that variable from being changed by subsequent operations. Before the block issues the value of the variable, it can accumulate data in variable components using several read operations - for instance, by assigning values from different parts of the text to different rows of the matrix variable. In addition, values read in one part of the text and stored in a variable can be substituted into other parts of the text using the Write value or Insert value operation.
Insert value¶
The Insert value operation is similar to the value substitution operation
Write value. You can use it to replace the entire contents of
the working frame with the variable value, or add strings above or below the
working frame and write the variable value in those strings.
Compared to the value substitution operation Write value,
the Insert value operation has the following additional settings:
-
Placement
You can choose one of the following ways to insert the variable value into text:
- Above the working frame - add strings to insert the value of the variable above the working frame.
- Replace the working frame - add strings to insert the value of the variable in place of the entire contents of the working frame (this will delete the current contents of the working frame).
- Below the working frame - add strings to insert the value of the variable below the working frame.
-
Transpose vector and matrix values
Use this setting to transpose the value of the vector or matrix variable before inserting it into text. If this check box is cleared, the components of the vector variable are placed on one text string; each row of the matrix variable is placed on a separate text string. If this check box is selected, the components of the vector variable are placed on adjacent text string, one component per string; each column of the matrix variable is placed on a separate text string.
-
Separate with
Use this setting to specify the field delimiter character on the string for inserting values of the variable components. You can select from the following characters: space character, tab character, semicolon, comma, or enter the desired character in the "Other" field.
Other settings are the same as for the Write value operation.
Python code¶
The Python code operation enables you to add the execution of the specified
Python script to the sequence of operations. Select this operation from the menu
to open the script editor.
In the editor window, you can enter, view, or modify a Python script that will
be executed as a single operation. Your script can import modules, define functions
and classes, etc., see Scripting for details. Note that this script
has the scope shared with all block operations, and the block variables listed in
the Variables pane are visible as global variables in this script.
Important
Your script must match the Python 3 syntax requirements.
Block ports¶
Each block variable can be assigned only an input port, only an output port, or a pair of input and output ports. The port name is the same as the variable name. A variable receives its values through the input port and emits its values through the output port. For details on setting and using variables, refer to the Variables section.
The following ports are provided for serving the input and output files:
- Input ports:
Input file path- specifies the input file path relative to the block's working directory. During a workflow run, the block expects to find the file by this path and name within its working directory.Output file path- sets the path where to write the output file, relative to the block's working directory. When the block runs, it stores its output file under this path and name.
- Output port:
Output file path- outputs the path where the block has stored its output file, relative to the block's working directory. You can use this port to pass the output file to another block in the workflow. Since the path is relative to the Text block working directory, that other block must have the same working directory in order to find the file.
See Input and output files for details on using the file path ports.
Each block option is assigned a separate input port. The port name is the same as the option name. Changing the value on the input port of a block option changes its setting accordingly. For a description of the option settings, refer to the Block options section.
The block provides a pair of signal ports: the @go input enables you to
control the startup of this block, the @go output signals that the
execution of this block is completed. A link to the @go input port ensures
that the block is only executed when a value is received on that port.
Linking to the @go output port allows you to delay the execution of
another block until this block has completed its operation and issued a
certain value on this port.
Scripting¶
All the Text block operations are actually function calls in the operations script. This script can be edited directly, allowing you to combine additional Python code with the Python code that implements standard block operations.
The Operations pane provides a command to open the dialog where you can edit the operations script, define your own functions and classes, import additional modules (see Built-in Python modules), etc. In the case of a long script, it is more convenient to use an external editor, and then copy the code from that editor into the operations script editing dialog.
Operations are called from the script using the methods of the template object,
which is an instance of the built-in class Template. Those methods are used
in place of standard Python file methods, since the operations script does not
provide direct access to the text file being processed by this block.
The block input and output variable names, listed in the Variables pane, are automatically added as global variables to the operations script namespace. You can also use global variables in the operations script without adding them in the Variables pane.
When the block starts running, the input variables in the script are automatically
assigned the values from the corresponding input ports. For example, if the block
receives some value on the input port my_invar, then the operations script
directive such as print my_invar will record that value to the workflow run log.
If the script assigns a value to an output variable, that value will be sent to the
corresponding output port when the block execution completes.
Important
Your script must match the Python 3 syntax requirements.
Template class¶
The built-in class Template represents the text file to process using this block.
The Template class object named template is automatically initialized in the operations script.
This section describes the methods on this object that you can use in your Python script.
template.insert()¶
insert(value, place='Above', delimiter=' ', transpose=False, format_style='No format', format_string='', format_decimal_separator='.')-
Insert data into the text file.
- Parameters:
value(float,int,str,bool,list,tuple,dict,numpy.ndarray) - the data to insertplace(str) - insert placementdelimiter(str) - field delimiter (a whitespace by default)transpose(bool) - whether to transpose vectors and matrices before insertingformat_style(str) - number formatformat_string(str) - number format specifierformat_decimal_separator(str) - decimal separator character
The
valueparameter can be a block variable (a value received to an input port), a general Python variable (assigned in the script), or a literal value.The insert placement specified by
placecan be:'Above'- add new lines above the working frame.'Below'- add new lines below the working frame.'Instead'- replace the working frame.
The
delimiterparameter is the sequence of characters to use as the field separator, empty string means no separators. The default delimiter is a single whitespace.Numeric values you insert into the text can be formatted with the
format_styleandformat_stringparameters. Theformat_styleparameter can be one of the following:'No format'- default Python formatting (as with%s). In this case, theformat_stringparameter has no effect.'C'- C-style formatting.'Fortran'- Fortran-style formatting.
In the case of C- or Fortran-style formatting, you can use the
format_stringparameter to supply the desired format specifier.Example of using the
Template.insert()method:# replace the working frame with the contents of my_matrix, # writing it transposed, # adding semicolon delimiters between numbers in each line, # and formatting numbers as floating point values with 5-digit precision template.insert(my_matrix, place='Instead', delimiter=';', format_style='C', format_string='%.5f', transpose=True) - Parameters:
See the Insert value operation description for more details.
template.read()¶
read(lines, fields, delimiter='', convert='Real')-
Read data from the text file.
- Parameters:
lines(str,int) - indices of text strings to read the data fromfields(str,int) - indices of string fields to read the data fromdelimiter(str) - field delimiter
convert(str) - the data type of the variable to cast the read data to- Returns: the read data
- Return type:
float,int,str,bool,list,tuple,dict,numpy.ndarray
The
linesandfieldsparameters can specify a comma-separated list of numbers and ranges (such as'1, 3-5, 8') or a Python slice (such as'2:9:2'or'-3:') - note that a list or slice of indices is a string (typestr). The index of an individual line or field can be an integer (typeint).The
delimiterparameter can take a regular expression. In this case, the field delimiter as any substring that matches the expression specified. If thedelimiterparameter is an empty string, the field delimiter is a substring consisting of one or more spaces or tabs.The return type depends on the data type set by the
convertparameter. This parameter is a string (typestr) that identifies the data type of the variable to receive the read data.Example of using the
Template.read()method:# fill a vector variable (assume its length is 6) using two read operations # read the first three fields from the third line of the working frame (index 2) # and store these values to the first 3 vector components my_vector[:3] = template.read(2, '1-3', delimiter=',|;|\/\/', convert='RealVector') # read other three fields (8-10) from the third line of the working frame (index 2) # and store these values to the next 3 vector components my_vector[3:] = template.read(2, '8-10', delimiter=',|;|\/\/', convert='RealVector') # the above operations recognize commas, semicolons, and double slashes as field delimiters # note that slashes must be backslash-escaped - Parameters:
See the Read value operation description for more details.
template.reset_frame()¶
reset_frame()-
Set the default beginning and end of the working frame. As a result, the working frame starts from the first line of the text file and ends on its last line.
Example of using the
Template.reset()method:# cover the entire text file with the working frame template.reset_frame()
template.set_frame_end()¶
set_frame_end(search, times=1, as_regex=False, shift=0)-
Set the end of the working frame.
- Parameters:
search(str) - search string or regular expressiontimes(int) - how many times to repeat the searchas_regex(bool) - treatsearchas a regular expressionshift(int) - move the specified number of lines down (or up, if negative) after completing the search
This method sets the new working frame end string as follows: moving up from the last string of the current working frame, search for the string matching the
searchparameter until the number of matching strings equals the value of thetimesparameter, and then move down or up from the last found string as specified by theshiftparameter.Example of using the
Template.set_frame_end()method:# starting from the current frame end, search upwards # for lines that match the regular expression ^=+endsub # (lines starting with one or more equal signs (=) followed by the word "endsub"), # skip the first matching line, stop on the second one, and then move 2 lines up template.set_frame_end('=+endsub', times=2, as_regex=True, shift=-2)See the Set frame end operation description for more details.
- Parameters:
template.set_frame_start()¶
set_frame_start(search, times=1, as_regex=False, shift=0)-
Set the beginning of the working frame.
- Parameters:
search(str) - search string or regular expressiontimes(int) - how many times to repeat the searchas_regex(bool) - treatsearchas a regular expressionshift(int) - move the specified number of lines down (or up, if negative) after completing the search
This method sets the new working frame start string as follows: moving down from the first string of the current working frame, search for the string matching the
searchparameter until the number of matching strings equals the value of thetimesparameter, and then move down or up from the last found string as specified by theshiftparameter.Example of using the
Template.set_frame_start()method:# starting from the current frame beginning, search downwards # for lines that match the regular expression ^=+sub # (lines starting with one or more equal signs (=)followed by the word "sub"), # skip the first and second matching lines, stop on the third one, # and then move 1 line down template.set_frame_start('^=+sub', times=3, as_regex=True, shift=1)See the Set frame start operation description for more details.
- Parameters:
template.write()¶
write(value, lines, fields, delimiter='', format_style='No format', format_string='')-
Write new data in place of existing data in the text file.
- Parameters:
value(float,int,str,bool,list,tuple,dict,numpy.ndarray) - the data to writelines(str,int) - indices of text strings to write the data tofields(str,int) - indices of string fields to write the data todelimiter(str) - field delimiterformat_style(str) - number formatformat_string(str) - number format specifierformat_decimal_separator(str) - decimal separator character
The
valueparameter can be a block variable (a value received to an input port), a general Python variable (assigned in the script), or a literal value.The
linesandfieldsparameters can specify a comma-separated list of numbers and ranges (such as'1, 3-5, 8') or a Python slice (such as'2:9:2'or'-3:') - note that a list or slice of indices is a string (type :type:str). The index of an individual line or field can be an integer (type :type:int).The
delimiterparameter can take a regular expression. In this case, the field delimiter as any substring that matches the expression specified. If thedelimiterparameter is an empty string, the field delimiter is a substring consisting of one or more spaces or tabs.Numeric values you insert into the text can be formatted with the
format_styleandformat_stringparameters. Theformat_styleparameter can be one of the following:'No format'- default Python formatting (as with%s). In this case, theformat_stringparameter has no effect.'C'- C-style formatting.'Fortran'- Fortran-style formatting.
In the case of C- or Fortran-style formatting, you can use the
format_stringparameter to supply the desired format specifier.Example of using the
Template.write()method:# write 3 values from the my_params vector # to the first (index 0) line of the working frame, # rewriting fields 7 to 9 in this line, # recognizing semicolons as field separators, # and formatting numbers as floating point values with 5-digit precision template.write(my_params[3:6], 0, '7:10', delimiter=';', format_style='C', format_string='%.5f')Example of using the
Template.write()method to write data from a dictionary variable (see Using quick selection for the purpose of such a variable):# one can write a dictionary to a table-like area in the text file, # if the dictionary keys are the same as the names of the table columns my_table = {"x1": [1.1, 2.1], "x2": [1.2, 2.2], "x3": [1.3, 2.3]} # each dictionary key corresponds to one column # write all columns from the my_table dictionary to the lines with # indices 2, 3, 4 in the working frame # the topmost line (index 2) must contain column headings template.write(my_table, '2-4', ':') - Parameters:
See the Write value operation description for more details.
Built-in Python modules¶
By default, the Text block provides a wide variety of Python modules
that you can import and use in the operations script, including numpy,
pandas, openpyxl, requests, and many more. If you import a module
in your script and get an ImportError exception, the module is most
likely not included with pSeven Enterprise. You can get a complete list
of available modules from the following script:
import pkgutil
from pprint import pprint
modnames = list(m[1] for m in pkgutil.iter_modules())
pprint(sorted(modnames))
Execute the Text block with this script within a workflow run, and then view the list of modules in the run log. If the module you need is not listed, it can be added to your workflow or to the block execution environment as described in the Adding modules section of the Python script block guide.
Block options¶
You can view or set block options in the Options dialog that appears when you click the Options button in the block configuration dialog. Block options can also be set through block input ports, each of which has the same name as the respective option.
The following options are used to indicate some features of the text to be processed:
- Decimal separator - specify the character to use as the decimal separator in the text representation of numbers.
- Line endings - specify how to end lines of text in the output file.
- Text encoding - specify the encoding of text in the template, input, and output files.
In the Options dialog, you can also specify the paths to the input and output
files (the Input file path and Output file path options). These options
actually set values of the Input file path and Output file path input ports
explained in the Input and output files section.
Decimal separator¶
Specify the character to use as the decimal separator in the text representation of numbers.
- Valid settings:
PointorComma - Default setting:
Point
This option specifies the decimal separator character used in the numeric
values that the block writes to the output text file or recognizes and
reads from the input text file, or from the quick selection area in the
template text. If the decimal separator in your template file is a comma,
then first of all select the Comma setting for this option, since this
setting affects how the block recognizes numeric values and fields in the
template text. For example, if a comma serves as a field separator, the
block might misinterpret a string of multiple numbers separated by spaces,
such as 1,001 2,201 3,311.
Line endings¶
Specify how to end lines of text in the output file.
- Valid settings:
WindowsorLinux - Default setting:
Windows
This option specifies which line endings will be used in the file the block
outputs: carriage return/line feed (CR/LF) or line feed only (LF) -
the Windows or Linux setting, respectively.
Text encoding¶
Specify the encoding of text in the template, input, and output files.
- Valid settings:
UTF-8,UTF-16,UTF-32,Latin1,Windows-1250,Windows-1251,Windows-1252,Windows-1253,Windows-1254,Windows-1255,Windows-1256,Windows-1257,Windows-1258,CP866, orKOI8-R - Default setting:
UTF-8
By default, the block assumes UTF-8 encoding in the template file, as well as
in the input and output files. If a different encoding is required, select
the appropriate setting for this option. The block will apply the encoding you
choose to all of its text files.