Python script¶
This guide provides an overview and brief instructions on how to use Python script blocks to execute Python scripts in pSeven Enterprise workflows.
Getting started¶
With Python script blocks, you can:
- Execute Python 3 scripts.
- Assign data from other blocks to script variables.
- Pass data from script variables to other blocks.
- Call other blocks to evaluate functions in the script.
- Drive iterative computations by calling other blocks in a loop.
Running a script¶
You enter your Python script in the configuration dialog of the Python script block. To open that dialog, double-click the block in the workflow.
Basically, the block runs the script when it has sufficient input data. For instance, if the block exposes any script variables through its input ports, it runs the script whenever all those variables get values.
You can configure certain script variables to get or pass their values through ports. To associate a variable with a port, add it in the Variables pane of the block configuration dialog, with the variable name the same as in the script. When you add variables in the pane, the block automatically creates associated ports. Input port values are assigned to variables at the start of the script; the values of variables are passed to the output ports upon completion of the script.
When associated with input ports, script variables can receive their values from various sources. A value entering a port through a link takes precedence and overrides the default value of the variable as well as any value assigned to the port in the Block properties pane. Similarly, a value assigned to the port overrides the default value of the variable. Thus, the block assigns values to script variables as follows:
- If there is a link connected to the variable's port, the block expects the variable's value from a link and will only use that value.
- If the variable's port is not linked anywhere but a value is assigned to that port in the Block properties pane, the script will use that value.
- If the variable's port is not linked and there is no value assigned to that port in the Block properties pane, the script will use the default value specified in variable's properties. This is intended mostly for testing (see Testing the script). Setting a default value allows script execution to start even if there is no value on the variable's port.
Script execution starts when each script variable associated with an input port receives a value. This can be the default value specified in variable's properties or a value from port. If at least one of such variables is not assigned a value, the block does not start script execution.
Variables associated with output ports can also be assigned a default value. This value is passed to the output port unless the script assigns a different value to the variable.
Exchanging data with other blocks¶
In a Python script block, you can assign values received from other blocks to script variables, as well as pass values of script variables from a Python script block to other blocks.
To receive or send a value of a script variable, associate that variable with a port:
- In the Variables pane of the block configuration dialog, add a variable with the same name as in your script.
- Set the appropriate direction of the port for that variable:
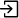 creates an input port for the variable.
creates an input port for the variable.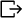 creates an output port for the variable.
creates an output port for the variable.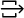 creates a pair of ports, input and output.
creates a pair of ports, input and output.
When you link the port of a Python script block variable with a port of another block, the Python script block receives or sends the value of the variable in accordance with the port direction setting.
Testing the script¶
When setting up a Python script block, it is often necessary to run the block script in order to check if it works as expected. For example, you might want to view debug information in the console or check the writing and reading of files. For testing and debugging purposes, the script can be run directly from the block configuration dialog.
To run the script in test mode, click the Run button in the upper right corner of the Script pane in the block configuration dialog. The button changes to Stop, allowing you to stop executing the script before it finishes. While running the script, its console output is displayed on the Log tab beneath the Script pane. The Results tab displays the values at the outputs of the block, obtained as a result of the script execution.
When running the script in test mode, you have to assign test values to all
variables associated with input ports (input variables), since in test mode
there are no values coming to those input ports. Referencing an input variable
with no test value in the script causes a NameError exception when the
script runs in test mode.
For a quick test, you can simply assign input variables in the script somewhere at the beginning, prior to referencing them. Keep in mind that you will have to remove or comment out these assignments when you finish testing the script: otherwise, during a workflow run your script will assign those test values to input variables every time it runs, so the block will effectively ignore values from input ports.
A safer way is to assign default values to variables in block configuration. In the Variables pane, open properties of a variable, check Use default and type a value in the Default value field below. When running the script in test mode, the default value from variable's properties will be assigned to the script variable. During a workflow run, default values of variables have the lowest priority (as explained in Running a script), so you do not have to clear defaults used while testing.
When run in test mode, the script can read and write files by relative path in its working directory, which in this case is the folder representing the working directory prototype for this Python script block in the workflow directory (see Working directories).
The Python script block can be configured to evaluate some functions in other blocks (see Calling other block to evaluate a function). Since the Python script block in test mode cannot call other blocks, script testing in this case ends with an error. To avoid this error, you could comment out calls to such functions while testing the script.
Usage guidelines¶
This section provides brief instructions for typical cases of using Python script blocks in pSeven Enterprise workflows.
Creating conditional branches in a workflow¶
When the script completes, some of the output ports of the Python script block may not get any value, so they do not output anything. This is not an error: it normally happens when the script does not set the value of a variable associated with an output port. Therefore, the script can choose a block to run after the Python script block by conditionally assigning a value to one or another variable.
Note
Variables involved in this kind of branching should not have default values. If the variable is not assigned in the script but it has a default, the block will output that default.
To take an example, consider a Python script block that runs a script, which tests some result for being "good" or "bad":
outcome = check(result)
if outcome == 'good':
# process a "good" result
elif outcome == 'bad':
# process a "bad" result
else:
# process other results
Let there be three more blocks named Good place, Bad place, and
Other place; each of them has a single input port named in. Suppose
that the Python script block that tests the result has to send "good"
results to Good place, "bad" results to Bad place, and everything
else to Other place:
- Create three variables named
good_result,bad_result, andother_result. Associate them with output ports. -
Assign variables in the script, depending on the test outcome:
outcome = check(result) if outcome == 'good': good_result = result elif outcome == 'bad': bad_result = result else: other_result = result -
Create links in the workflow:
- Link the
good_resultoutput to theinport of theGood placeblock. - Link the
bad_resultoutput to theinport of theBad placeblock. - Link
other_resultto theOther placeblock.
- Link the
The above configuration creates three mutually exclusive workflow
branches. The Python script block triggers one of these branches by
sending the value of result to one of its output ports.
Calling other block to evaluate a function¶
If your script uses a function that is impractical to evaluate in the script itself, you can put the evaluation in a separate block. This feature is especially useful when implementing iterative procedures or when using functions that are evaluated by two or more blocks running in parallel.
To delegate the evaluation of a certain function to another block, declare that function in the Python script block configuration:
- In the Functions pane of the block configuration dialog, add a function and assign it the name of your script function to be evaluated in another block.
This function declaration creates a so-called response port in your Python script block, with the port name the same as the function name.
The function is required to have at least one argument to communicate with its evaluation block. Argument values must be passed from the script to the block that evaluates the function. To pass argument values, declare those arguments in the Python script block configuration:
- In the Arguments pane of the block configuration dialog, add the arguments to pass to the function evaluation block. Name the arguments as you see fit.
- In the Functions pane, add arguments to the function declaration. The argument names must be the same as in the Arguments pane.
This declaration creates a so-called request port in your Python script block for each declared argument, with the port name the same as the argument name.
For a specific block to evaluate the function, the request and response ports must be properly linked to the ports of that block:
- Link the request ports of the Python script block to input ports of the function evaluation block.
- Link the output port of the function evaluation block to the response port of the Python script block.
With these link settings, the script function is evaluated as follows:
- The script calls the function with the given argument values, and waits for the function to return a value.
- The Python script block passes the argument values to the request ports for delivery to the input ports of the function evaluation block.
- The evaluation block receives the argument values, evaluates the function, and passes the value to the output port for delivery to the Python script block.
- The Python script block receives a value on the response port and passes it to the script as the return value of the function.
Controlling a loop in a workflow¶
The ability to invoke function evaluation blocks by calling functions in
the script enables the Python script block to control cycles that
involve executing other blocks. For example, solving an optimization
problem requires many iterations, each of which involves executing the
same function evaluation block - let's name it Objective. Suppose the
Objective block has two input ports x1 and x2, and an output port
f. In this example, a Python script block can be used to implement
optimization iterations as follows:
- Populate the block with a script that calls a certain function in a
loop. Suppose this function is named
objectiveand has two argumentsx1andx2. - In the Python script block configuration dialog:
- Add
x1andx2in the Arguments pane. - Add
objectivein the Functions pane. Add thex1andx2arguments to theobjectivefunction you have added.
- Add
- Link the request ports
x1andx2of the Python script block to the input portsx1andx2of theObjectiveblock. - Link the output port
fof theObjectiveblock to the response portobjectiveof the Python script block.
As a result of this configuration, the Python script block calls the
Objective block in a loop, causing it to evaluate the objective
function at each iteration with new argument values.
Calling several blocks concurrently¶
As discussed earlier (see Calling other block to evaluate a function), you can configure the Python script block to invoke some additional block when the script calls a particular function. Many real-life scenarios require the ability to invoke a number of additional blocks and execute them in parallel. For example, in optimization tasks the objective and constraint functions are often evaluated by different blocks. To run these blocks in parallel, you can use a specific syntax for concurrent function calls explained here.
Suppose you need to evaluate two functions, F and C, which are
functions of one argument x, and you use two separate evaluation
blocks:
- A block named
Objective, which has an input portxand an output portf. This block evaluatesF. - A block named
Constraint, which has an input portxand an output portc. This block evaluatesC.
In this example, you can call the evaluation blocks as follows:
- In the Python script block configuration dialog:
- Add
xin the Arguments pane. - Add
FandCin the Functions pane. Add thexargument to both of these functions.
- Add
- Link the request port
xof the Python script block to the input portxof both theObjectiveandConstraintblocks. - Link the output port
fof theObjectiveblock to the response portFof the Python script block. - Link the output port
cof theConstraintblock to the response portCof the Python script block. -
Use the following call syntax in your script:
objective, constraint = (F&C)(x)
During script execution, the objective variable will be assigned the
value received on the response port F, and the constraint variable
will be assigned the value received on the response port C. Execution
of the script continues only after the block has received both values.
This example can be naturally extended to call three or more function
evaluation blocks at the same time: declare the arguments and functions
in the Python script block configuration dialog as described above,
and call functions by concatenating them with &, such as
f1, f2, f3 = (F1&F2&F3)(x1, x2, x3). To improve code readability, you
can also use the following syntax:
all_functions = function_1 & function_2 & function_3
f1, f2, f3 = all_functions(x1, x2, x3)
Exchanging data with a REST client¶
A REST client can exchange messages with blocks in a running workflow. This messaging mechanism enables Python script blocks to receive and send messages to the REST client. Thus, you can configure a Python script block to wait for a message from the client, and then process the message data to produce output.
For details on how to send or receive messages from a script, see section Messaging in the REST API guide.
Caching Python objects¶
When using the Python script block, you may need to retain some data between block runs within a single workflow run. For example, if a Python script block is repeatedly run in a loop, saving certain objects between block runs and reusing saved objects can significantly speed up the calculation. Typically, these are objects (variables, data arrays, class instances, etc.) that take a long time to initialize and remain unchanged during the workflow run.
Saving objects for reuse in subsequent block runs is referred to as caching objects. You can cache an object to avoid initializing it each time the block is run. Caching stores the object after the script finishes executing and enables the script to use the stored object without reinitializing it in future runs.
To cache objects, import the api module and then use the
api.cache dictionary:
import api
my_class = MyClass()
api.cache['my_class_label'] = my_class
In this example of caching, the my_class object is stored in the
api.cache dictionary under the 'my_class_label' key. In subsequent
block runs, the cached object can be retrieved from the api.cache
dictionary by using that key.
When you use caching, keep in mind that the cached object is not
guaranteed to be kept in the cache. Having stored an object in the
api.cache dictionary, the script must check for the existence of the
object in the cache. Possible reset of the cache between block runs may
result in the deletion of cached objects. If the cached object has been
deleted, the script must initialize the object and store it in api.cache
again:
import api
try:
my_class = api.cache['my_class_label']
except KeyError: # Object is missing from cache.
my_class = MyClass()
api.cache['my_class_label'] = my_class
This example tries to retrieve an object from the api.cache dictionary
using the known key. In case of a KeyError exception, indicating that
the object is not in the cache, the object is initialized and cached again.
Note that the first time the block is run, the object is obviously not
in the cache, so it will be initialized and stored in api.cache.
Saving data for reports¶
pSeven Enterprise provides reports for viewing and analyzing data obtained
during the execution of the workflow. To transfer data to a report, it must be
saved as a .p7table file (see
Analyzing computation history files).
You can use the Python script block to write data to .p7table files:
import the api module and use api.write_report_table().
api.write_report_table(path, data)-
Save data to a
.p7tablefile, so it can be loaded into a report.-
Parameters:
path(stringorpathlib.Path) - the target.p7tablefile name and path relative to the block's working directorydata(pandas.DataFrame) - a table received through an input port, or apandas.DataFramewith named columns
-
Returns: the path and name of the saved file (
pathlib.Path) - Raises:
FileNotFoundErrorifpathpoints to a folder that does not exist
Writes
datato a.p7tablefile located bypathrelative to the block's working directory. Yourdatamay be a table created by another block and received through a port, or apandas.DataFramewith named columns initialized in your script. Other data types must be converted topandas.DataFramefirst. Named columns are required.If the
pathparameter specifies the path to some folder in the block's working directory, this folder must be created in advance, otherwisewrite_report_table()raises aFileNotFoundErrorexception.If the file specified by the
pathparameter already exists, overwrites it without warning.The
.p7tablefile name extension in thepathparameter is optional: if omitted, it will be added automatically. -
Saving a table received from another block
Example: get the table through the input port and
save it to results.p7table in the block's working directory root.
# Assuming solver_results is the variable associated with the input port
# that receives the table (results) from another block (the solver).
import api
from pathlib import Path
table_path = Path("results.p7table")
table_path = api.write_report_table(table_path, solver_results)
print("Saved the results table to {}".format(table_path))
Saving a NumPy array
Example: convert a NumPy array to pandas.DataFrame and
save it to results.p7table in the block's working directory root.
# Assuming results_arr is a 3-column NumPy array
# initialized in the block's script or received through an input port.
import api
import pandas as pd
from pathlib import Path
table_path = Path("results.p7table")
table_data = pd.DataFrame(results_arr, columns=["x1", "x2", "f"]) # named columns required
table_path = api.write_report_table(table_path, table_data)
print("Saved the results data to {}".format(table_path))
Using signal ports¶
The Python script block provides a pair of special signal ports: the @go
input enables you to control the block startup, the @go output signals that
the block has finished execution.
The @go input port is commonly used when your Python script block does not
need port data from other blocks to start (does not have any ports that
require inputs), yet you want it to start only after another block in the
workflow has finished. If you connect a link to the @go input, your
Python script block will start only after it receives a signal to that port.
As a note, the same goes for blocks that do expect data from other blocks: if
your Python script block data inputs are connected to other blocks, and its
@go input is also connected, then that block starts only after it has
received all the necessary data - and the signal to the @go input.
Any value received to the @go input works as the signal. Usually that value
comes from the @go output port of a preceding block, however you can send
any data to the @go input to achieve the same behavior. The actual value
received to @go is of no significance: that value only informs the block
that it may start execution, otherwise it is not used, and you cannot access
it in the block's script.
The @go output is a self-explanatory complement of the @go input: when
the block finishes, the @go output port issues a value that you can use as a
signal to the @go input port of another block; the value itself is of no
significance.
Working directories¶
When a Python script block starts in a workflow run, the block working directory becomes the current working directory of its script. The script can read and write files in this directory.
In the simplest case, when the Python script block is placed at the top level in the workflow (not nested in a Composite), its working directory is the workflow run directory. Files you upload to the workflow directory on the Files tab in Explorer will be available to the block during a workflow run, as they are copied to the run directory when starting the workflow execution.
To set up a different working directory for your Python script block,
you need to nest it in a Composite block. In this case, the working
directory of the parent Composite block serves as the working
directory for the child Python script block. In particular, this
allows you to set up the workflow so it creates a new working directory
for the Python script block every time it starts during a workflow
run: set the working directory type of the parent Composite block to
indexed as explained below.
- Select one or more Python script blocks in the workflow and click
 on the workflow toolbar to
group the selected blocks into a new Composite block. If you have
selected multiple Python script blocks to group, all of them will
have the same working directory.
on the workflow toolbar to
group the selected blocks into a new Composite block. If you have
selected multiple Python script blocks to group, all of them will
have the same working directory. - Uplink inputs and outputs of nested blocks to pass data between them and blocks outside the created Composite block (see Uplinks). Alternatively, you can link blocks before grouping - in this case, all required uplinks are created automatically when you group blocks.
-
Select the created Composite block and configure its working directory using the Working directory options in the Composite properties pane on the right:
- To use the same working directory during a workflow run, select
single. With this setting, child Python script blocks will work in the same directory every time they start during a run. The workflow run directory prototype holds the prototype of this working directory, which is a folder with the name of the Composite block. Upload input files for the Python script blocks to that folder on the workflow directory Files tab in Explorer. - To create a new working directory every time the Composite block
and its child Python script blocks start during a workflow run,
select
indexed. This setting is useful, for example, if you set up a working directory for blocks from the body of a workflow loop: a new working directory with an indexed suffix will be created at each iteration of the loop. The child Python script blocks may write files to their working directory, and files written at different loop iterations will not overwrite each other. In the workflow run directory prototype, the prototype for the indexed working directory is a folder with the name of the Composite block followed by the[####]suffix. Files uploaded to that folder will be available to the Python script blocks at each iteration of the loop, because they are copied to every new indexed working directory created during a workflow run.
- To use the same working directory during a workflow run, select
The above explains only the basic and most commonly used working directory setups. For more information on working directories, see Working directory management.
Working with files¶
The Python script block is able to read and write files in persistent or temporary storage. Here are some typical use cases for this feature:
- Reading files containing input data. When setting up the workflow, the file is uploaded to the the Python script block's working directory prototype on the workflow directory Files tab in Explorer. During a workflow run, the script can open this file in the block's working directory.
- Temporary file storage. The script can save files in the temporary directory of its Python script block. Those files are inaccessible to other blocks and are deleted upon completion of a workflow run.
- Saving results to a file. To preserve a file after the workflow run is completed, the script can write it to the working directory of its Python script block. The file saved in this way will be available in the workflow run results.
For more information on choosing where and how to store your files, see Best practices for file handling.
Reading files containing input data¶
Files that you upload to the block's working directory prototype on the workflow directory Files tab in Explorer, are copied to the block's working directory once you start a workflow run. To read such a file, use its relative path in the working directory:
with open('params.csv', 'r') as f:
parameters = f.read()
In this example, parameters are read from a file located in the root of the block's working directory. This assumes that the file was uploaded to the root of the block's working directory prototype on the Files tab in Explorer.
Sometimes you may need your script to read a file that is automatically copied from the workflow directory root to the root of the current run directory, or in the case of a referenced workflow - to the root of the working directory of the Composite block containing the referenced workflow (see Referencing workflows). You may also need your script to read a file located in the root of the workflow directory. For details on these file location options, see Best practices for file handling.
To compose the path to a file being copied from the workflow directory
root, use the @Working directory path internal port of the workflow:
add a script variable and connect its port to the @Working directory path
internal port of the workflow, and then compose the path to the file
from the file name and the value of that variable. This way you will
get the correct path to the file both in the case of directly running
the workflow and in the case of running the workflow by reference. In
the latter case, through the link with the @Working directory path port,
your script receives the path to the folder into which the file from
the root directory of the referenced workflow is copied when running
the main workflow.
To compose the path to the file in the workflow directory, import the
api module and use the following variable:
api.wfdir-
- Type:
pathlib.Path
Path to the workflow directory. In the case of the referenced workflow, the value of this variable is the path to the directory of the main workflow.
- Type:
The join operator for pathlib paths is /.
For example, any Python script block, regardless of its working
directory settings, can read a file from the workflow directory:
import api
# read infile.dat from the workflow directory root
infile = api.wfdir / 'infile.dat'
with infile.open() as f:
data = f.read()
To get the path to the run directory, you can use the following
variable from the api module:
api.rundir-
- Type:
pathlib.Path
Path to the current run directory. In the case of the referenced workflow, the value of this variable is the path to the run directory of the main workflow. To get the path to the folder into which the referenced workflow's run directory prototype is copied, use the link to the
@Working directory pathinternal port in the referenced workflow, as described above. - Type:
Temporary file storage¶
The Python script block can write and read temporary files during a workflow run. The preferred location for such files is the block's temporary storage directory, as the block can access files in this directory much faster than in other directories.
Each block has its own temporary storage directory, and does not have access to such directories of other blocks. Files in the temporary storage are kept while the block is running. After the block finishes executing its script, the temporary files it has created may be automatically deleted by pSeven at any time. Upon completion of a workflow run, all temporary files generated by this run are deleted, if they have not been deleted earlier.
To compose paths to files in the temporary storage directory, import the
api module and use the following variable:
api.tempdir-
- Type:
pathlib.Path
Path to the block's temporary storage directory.
- Type:
For example, to save some data to a temporary file:
import api
# save data to tmp.dat in the temporary storage
tmpfile = api.tempdir / 'tmp.dat'
with tmpfile.open(mode='w') as f:
f.write(somedata)
Saving results to a file¶
When running a workflow, a run directory is created that holds working directories for the blocks of that workflow. The script can write files in its Python script block's working directory by relative path, for example:
with open('results.csv', 'w') as f:
f.write(result_data)
In this example, the script writes the result data to a file located in the working directory root. In workflow run results, this file is found in the folder representing the block's working directory.
Best practices for file handling¶
Follow the recommendations below when working with files in a Python script block:
-
If the block needs to read input data from a file, upload that file into the block's working directory prototype on the workflow directory Files tab in Explorer. During a workflow run, the file is copied to the block's working directory, and the script should open it by relative path.
In many simple workflows, the block's working directory is the same as the current run directory. In this case, upload the file to the root of the workflow directory on the Files tab, and open it by relative path.
-
If you need to provide access to a certain file to several blocks with different working directories, and you do not want to create several copies of the file, upload that file to the workflow directory root on the Files tab in Explorer. During a workflow run, the file is copied to the root of the current run directory, or in the case of a referenced workflow - to the root of the working directory of the Composite block containing the referenced workflow (see Referencing workflows).
Any block will be able to open such a file along the path to its containing folder retrieved from the
Working directory pathinternal port of the workflow: add a script variable and connect its port to theWorking directory pathinternal port of the workflow, and then compose the path to the file from the file name and the value of that variable.To avoid conflicts, the blocks should open the file for read-only.
-
If you do not want to copy a certain file at each run, upload that file to the workflow directory on the Files tab, and then prevent its copying by applying the Run files rules Do not copy to the workflow run command from the menu in the Explorer pane. In the case of a referenced workflow, the file must be uploaded to the directory of the main workflow. Any block will be able to open such a file along the path to the workflow directory retrieved from the
api.wfdirvariable.This file location setup requires the following:
- All blocks that need the file, open it for read-only.
- The file remains unchanged during the run, that is, you do not edit, re-upload or otherwise change the file while the workflow run is in progress.
-
If you need to write data to a file, create the file in the temporary storage directory. Writing and reading files in the temporary storage directory works much faster compared to other directories. Files in this directory are kept while the block is running, but may be automatically deleted by pSeven at any time after the block finishes executing its script. The path to a file in the temporary storage directory can be composed using the
api.tempdirvariable. - If the block is part of a workflow loop, and you need to write a file
and preserve it between iterations of the loop, do not place the file
in the temporary storage directory, as it may be deleted automatically.
If possible, save the file to the block's working directory. If the
block uses a different working directory at each iteration, save the
file to the current run directory using the
api.rundirvariable - but make sure that other blocks do not write to the same file, to avoid conflicts. -
If you need to save a file in run results, create the file in the block's working directory. To access a file in the working directory, use its relative path. After completion of the workflow run, the file is located in the folder representing the block's working directory in the given run directory.
If the block creates many files, some of which need to be made available in run results, create files in the temporary storage directory and copy only the required files to the working directory.
-
If a block needs to read files being created by another block, configure the blocks so that they have the same working directory. For example, you can enclose both blocks in a Composite block, which will make the working directory of the Composite block their common working directory. Use relative paths to access files in the working directory.
Observe the following basic rules when you choose where to store files being produced by a Python script block:
- In the working directory, store only those files that are needed as workflow run results. Saving large files or a large number of files to the working directory can significantly slow down the workflow run, since such an operation is time-consuming and resource-intensive.
- Use temporary files to store intermediate work results that will not be needed after the completion of the workflow run. Do not store intermediate results in the working directory, as this can negatively affect the performance of your workflow.
- Use temporary files whenever possible, as operations with such files are much faster. For example, if a Python script block launches a program that creates a large number of files, always specify the temporary storage directory as the working directory for the program. If any program output files need to be saved in the run results, copy those files from the temporary storage directory to the block's working directory in your script.
Python version¶
To run your script, the Python script block uses Python provided with pSeven Enterprise, which is a certain up to date version of Python 3.
You can check the exact version number in the block configuration dialog, the Configuration pane.
Python modules¶
By default, the Python script block provides a wide variety of Python modules, which you can import and use in the script:
- Most of the modules commonly used for scientific and technical
computing, including
numpy,tensorflow,scikit-learn,pandas,openpyxl,requests, and many more. - The pSeven Core modules.
If you import a module in your script and get an ImportError exception, it
means that the module is not included in the pSeven Enterprise Python
distribution. In that case, you can:
- Check the full list of available modules as described in Listing modules to find an alternative to the unavailable module.
- If the module you need comes from a pure Python module distribution, add it to your workflow as described in Adding modules.
If there is no exception on module import but you get warnings or errors, it
may mean that nodes of the cluster where pSeven Enterprise runs do not satisfy
that module's system requirements. For example, import tensorflow may fail
with the following error:
The TensorFlow library was compiled to use AVX instructions, but these aren't available on your machine.
The error means that CPU of the cluster node where your block was executed does not support the AVX instruction set, which is required by TensorFlow. For such errors, there are no advisable workarounds - notify your deployment administrators about an unsupported module and let them resolve the issue.
Listing modules¶
You can get a complete list of available modules from the following script:
import pkgutil
from pprint import pprint
modnames = list(m[1] for m in pkgutil.iter_modules())
pprint(sorted(modnames))
The list created in this way contains names of all modules available on the
node where the script is executed, and may differ for different nodes. For
example, TensorFlow (the tensorflow and keras modules) and pSeven Core
(the da.p7core package modules) are not installed by default on Windows
extension nodes. Therefore, to get the correct list of modules, you should
execute the block with this script within a workflow run, and view the list
of modules in the run log.
You can also get the list of modules by test running the above script (see Testing the script). The list will appear on the Log tab in the block configuration dialog. The list of modules obtained in this way can be considered correct if the block is configured to run on any available node of the pSeven Enterprise cluster (in the Block properties pane, Run on: is set to "any host").
Adding modules¶
Apart from the modules that are available by default, you can add more modules. The module distribution and all its dependencies must contain only Python code. Such distributions are commonly referred to as pure Python module distributions.
To add a module, follow these steps:
- In Explorer, navigate to your workflow directory.
- On the Files tab in the Explorer pane, create a folder to hold
your module files. Let the folder name be
lib. - Upload your module files to the
libfolder.
Let's say your module is called extra_module. Then you can import it
in the script like this:
import sys
import api
sys.path.append(str(api.rundir / 'lib'))
import extra_module
Note that if you import additional modules in different blocks, there is no
need to create a separate folder for each block. It is advisable to store
all additional modules in one lib folder within the workflow directory.
Modules added in the way described above can only be used within the given workflow, and provided that the block is configured to run on any available node of the pSeven Enterprise cluster (in the Block properties pane, Run on: is set to "any host"). To enable the use of additional modules within any workflow, as well as in blocks running on Windows extension nodes, the modules must be installed in the block execution environment on the pSeven Enterprise cluster and on extension nodes. A pSeven Enterprise deployment administrator is required to install additional modules in the block execution environment; for installation instructions, see Installing additional Python modules in the pSeven Enterprise administration guide.
Keyboard shortcuts¶
When composing a script in the configuration dialog of the Python script block, you can use keyboard shortcuts to perform the following tasks:
| Task | Windows, Linux | Mac |
|---|---|---|
| Save script and configuration changes | Ctrl+S | Cmd+S |
| Find a match | Ctrl+F | Cmd+F |
| Find the next match | Ctrl+G | Cmd+G |
| Find the previous match | Shift+Ctrl+G | Shift+Cmd+G |
| Find and replace a match | Shift+Ctrl+F | Cmd+Option+F |
| Replace all matches | Shift+Ctrl+R | Shift+Cmd+R |
| Jump to line number | Alt+G | Option+G |